

Removing the bottlenecks in Engineering AI
Transitioning to AI Engineering of the physical world


Engineering systems are getting more complex, and at the same time the pressure to ship them faster is increasing. Teams that can explore more of the design space and iterate faster have a decisive advantage.
More and more tools are being built for running automated simulation workflows, to power design of experiments and optimisation algorithms, and to generate enough data to enable AI. To make use of this data, engineering teams also need powerful platforms for understanding it and which can work within a collaborative, iterative design process.
But to get this data in the first place, you need to automate a full pipeline from generating geometry to post-processing simulation results.
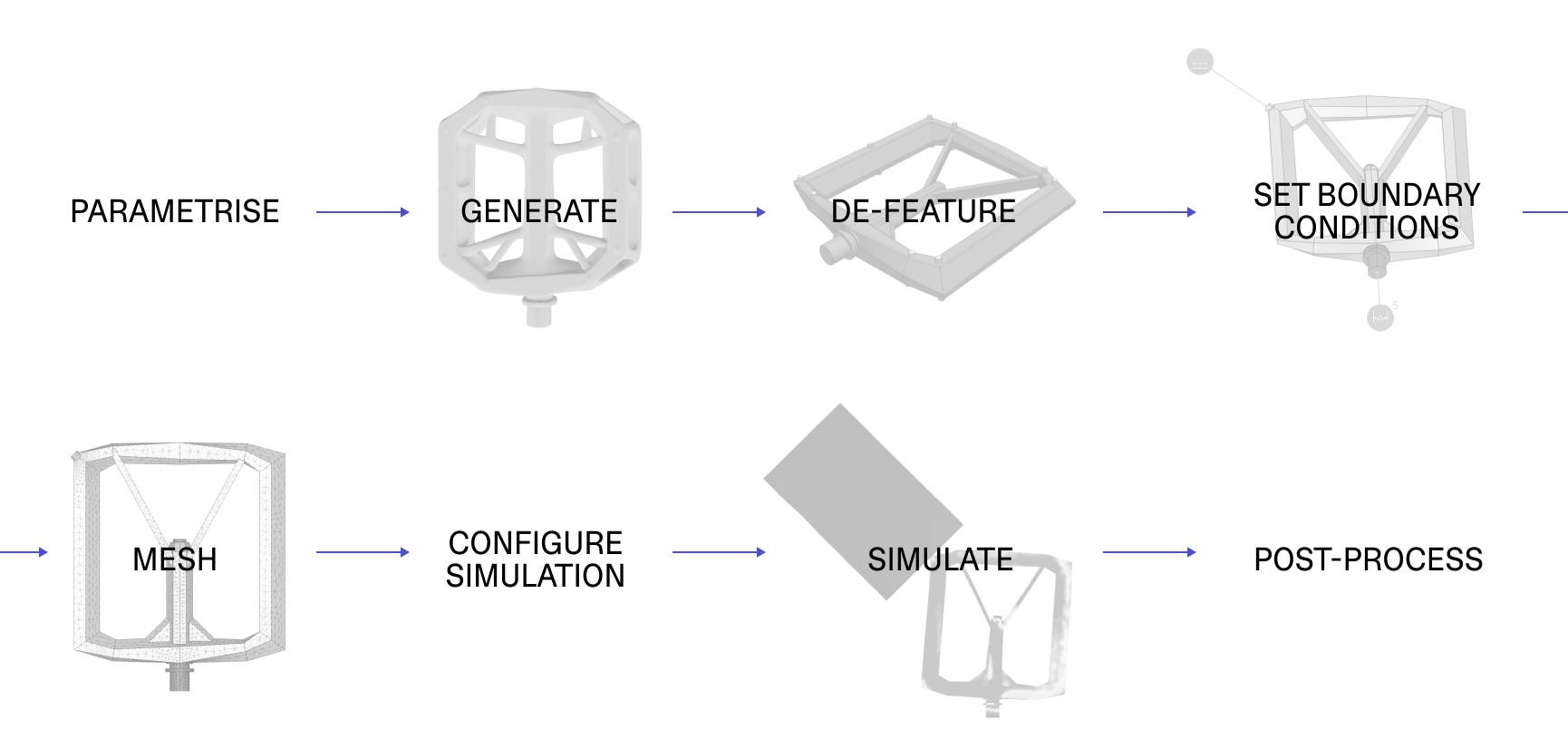
The most visible steps get a lot of attention: generate and simulate: creating a valid geometry, and then spending significant compute time on running physics simulations. Either of these steps breaking or slowing down is a clear target to improve.
But we’ve been doing this with real engineering teams across industries for years (see our case studies in bioreactors, robotics, or architecture), and the bottleneck to making use of this pipeline isn’t either of these steps. It’s the cognitive challenge of building parametric versions of all the other steps that an engineer usually does manually.
The cognitive challenge of automated pipelines
In all of the engineering problems we’ve worked on, setting up the pipeline means: writing automation logic, connecting tools together, debugging, and thinking through how parametric changes affect everything from geometry to post-processing of simulation.
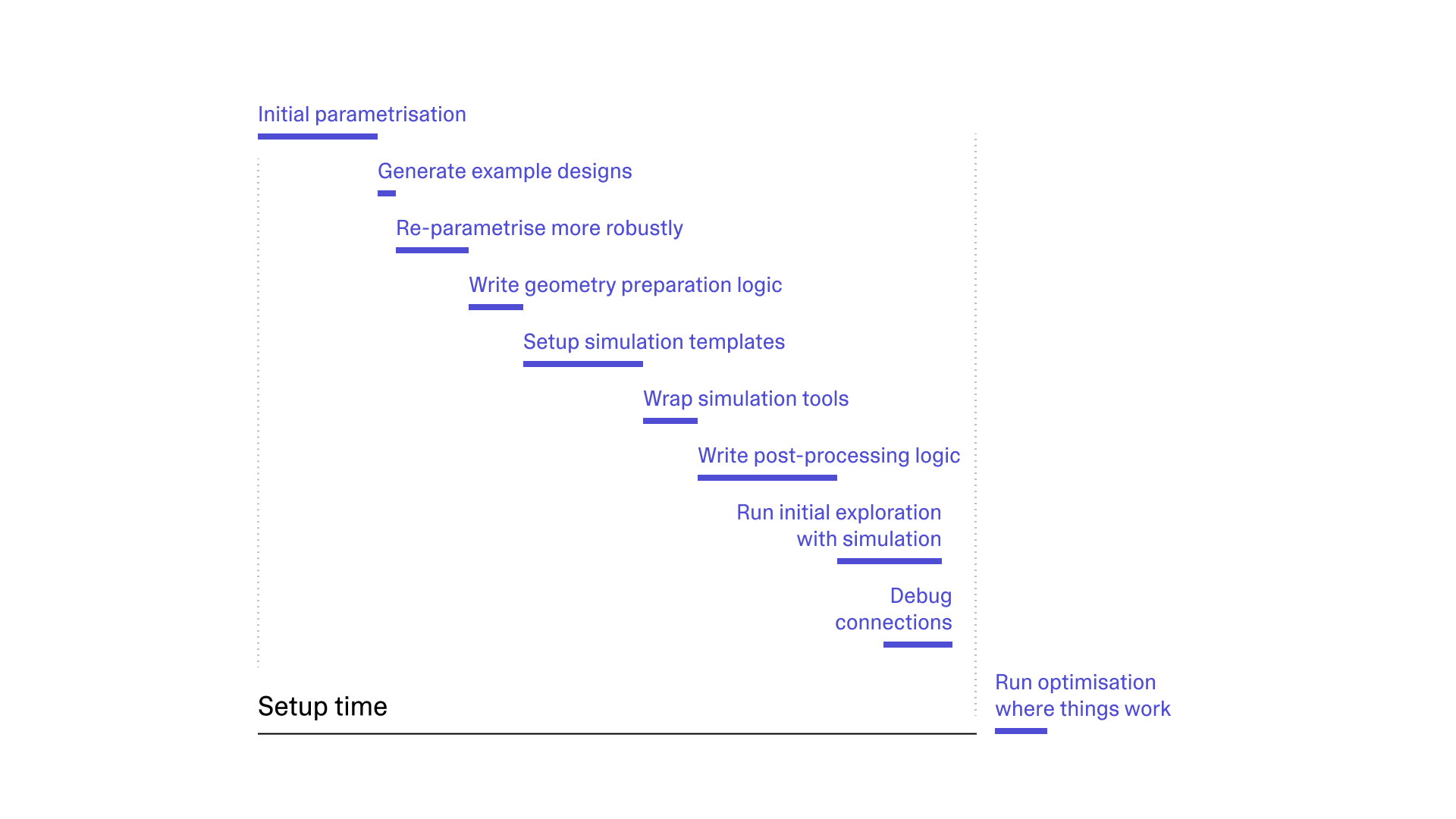
All of these steps need to happen regardless of what geometry tool you use, which scripting language, or what simulation package. More robust geometry kernels (like implicit models) don’t produce a broken BREP when you push parameters to unexpected places, but that doesn’t reduce the core cognitive challenge: deciding what should vary, what stays coupled, and where the boundaries are. Additionally, if you want to use physics AI, you still need all of this first – plus model training and validation. During inference, you can often skip meshing and other preparation steps, but still need this full pipeline for training.
While you’re going through all of these steps, there is a key question to answer: “by the time this pipeline is set up, what kind of design iterations will we be exploring”? You’re trying to predict the future, while the design is actively changing.
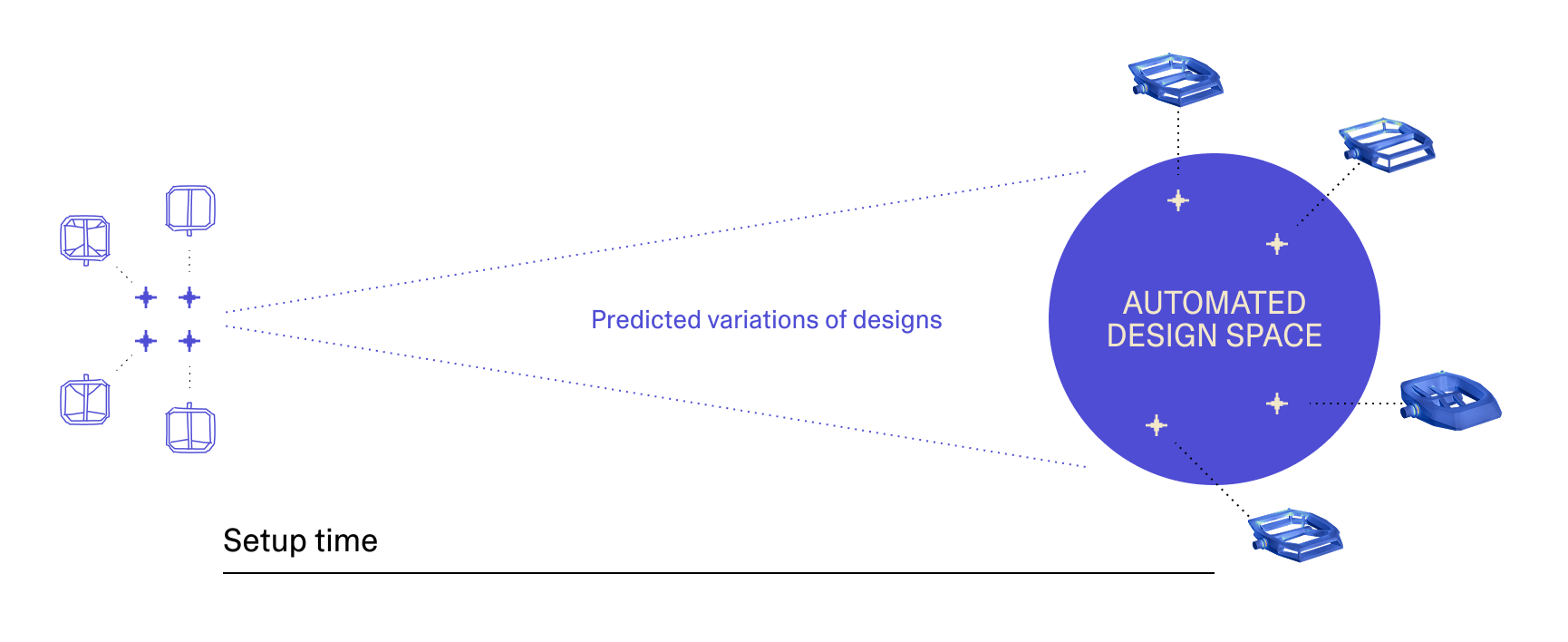
Only the changes compatible with the automation you’ve set up can be explored. But because of the iterative nature of engineering design, by the time the pipeline works, the design has already moved on. The more iterative you are, the better your engineering process; but the faster the design evolves the more challenging this prediction becomes.
This is why most tools for automating this pipeline create monolithic workflows that only the author can iterate on. The computational engineer becomes the single point of dependency.
One emerging response is to try and build AI agents that handle simulation setup on the fly. Agents can be incredibly powerful with the right tools and skills, but using them on every new design shifts where the expertise is needed rather than reducing it. Without a verifiable environment of known-good cases to validate against (or until we can completely trust AI’s output in engineering), someone still needs the expertise to judge when the agent’s choices are subtly wrong. And running a probabilistic agent within the pipeline itself isn’t an option when you need fully traceable results.
The challenge is to make agents work to speed up this automation pipeline in a way that supports the reality of engineering design iterations.
Beyond parametric design changes
Setting up a parametric pipeline is challenging in itself, but engineering iteration rarely stays parametric. Real design changes aren’t “adjust this fillet from 2mm to 4mm.” They’re “split this into two components,” “try a different mounting approach,” or “the supplier says this material isn’t available.” These are new designs, not parameter tweaks.
These beyond-parametric changes aren’t edge cases — they’re the norm. If you’re working with an industrial designer, you might receive a render or just a surface, not full CAD. A supplier sends a scanned part in a different format. A design review produces an annotation sketched directly onto the model. They don’t fit parametric models, but they still need to be evaluated. In our experience, the computational engineer responsible for the parametric workflow often doesn’t have the time to adapt the automated workflows to fit these new directions.

For automated simulation pipelines to remain useful across actual design cycles, they have to accept design ideas that weren’t anticipated when it was created.
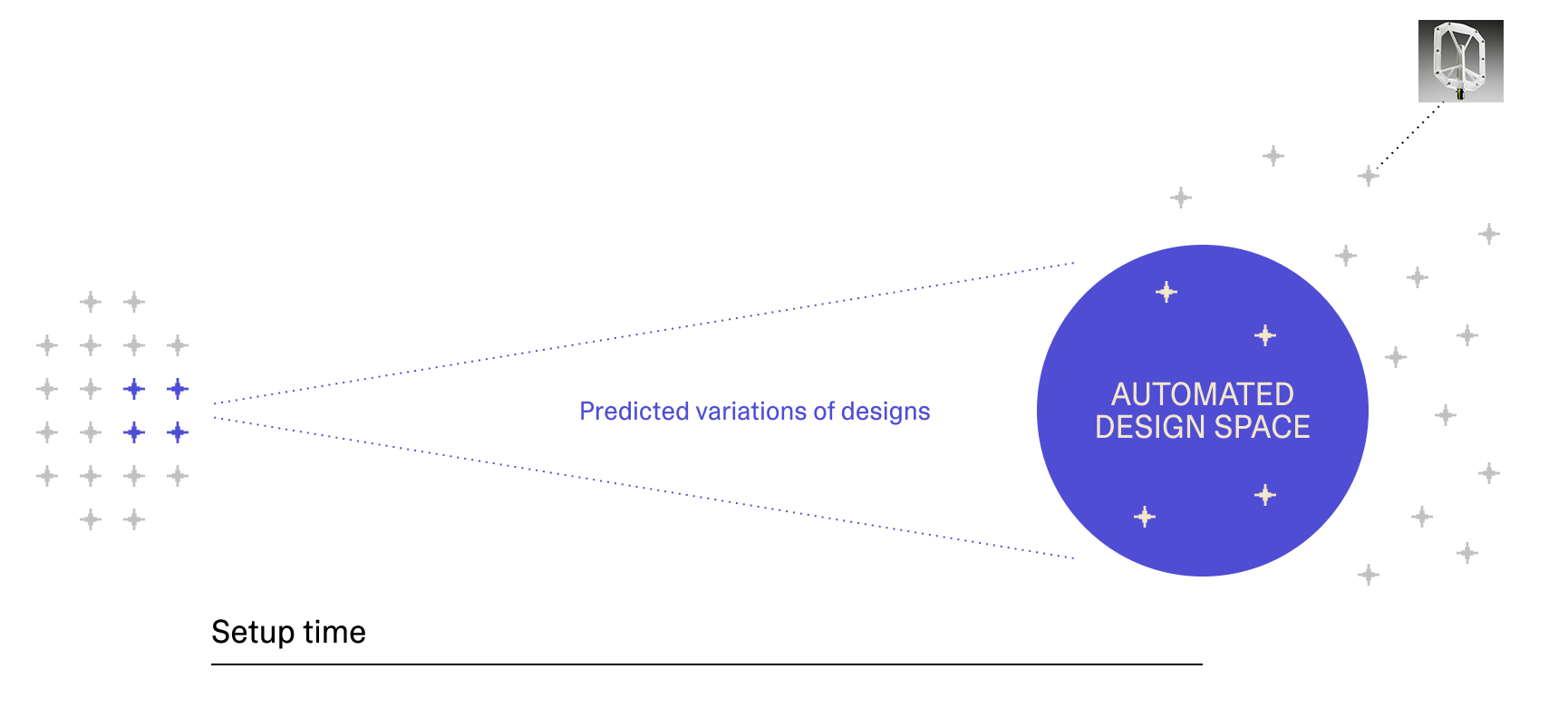
One approach would be to make the automated design space large enough to cover everything. This is what physics foundation models, or large geometry models, are attempting. But simulating physics isn’t about learning high-level concepts from more data; it’s about precise mathematical relationships in fundamentally chaotic systems, and LLMs haven’t yet demonstrated reliable geometric reasoning. Whether foundational models for geometry or simulation can be built in practice remains an open question.
Rather than trying to make the scope of automation larger, we reduce the setup cost so automation can evolve with the design.
Trust experts in simulation, accelerate geometry
Over many years we have made an observation that helps: simulation templates are far more reusable than parametric geometry models.
The criteria you evaluate against — fatigue life, static stress, mass, cost — stay stable across design iterations, even as the geometry changes radically. A simulation setup defines boundary conditions, meshing strategies, convergence criteria, and de-featuring rules. These define the problem, not the design. A single simulation setup can handle far more geometry variation than a monolithic geometry model.
In our platform, the simulation template remains human-defined because that’s where trust and expertise matter. We use AI to accelerate the expert creating these templates, but keep the expert accountable, and instead we speed up the rest of the pipeline.
Automation that evolves iteratively
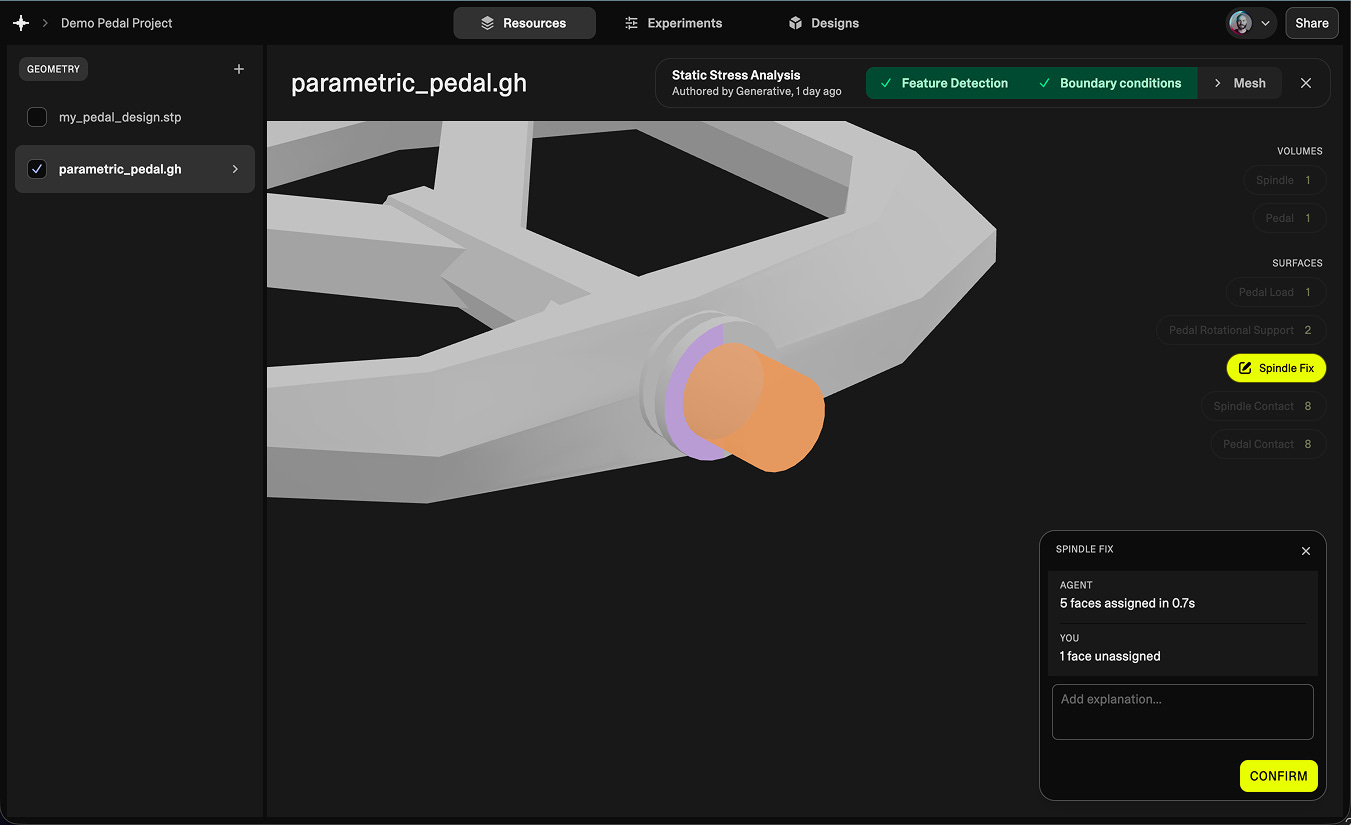
To reduce the setup time for automation (in order to enable the data-driven decisions that engineering teams need to move faster), we focus on all the steps around generation and simulation. We’ve developed AI agents to write the automation logic itself for parametrising geometry, feature-detection, geometry-preparation, meshing, configuring simulation, and post-processing. This removes the need for an agent to reason about each design at runtime, keeping all automation logic deterministic and traceable.
We create a continually growing set of verification cases for the agents to work with from successfully simulated examples and all human-defined designs (specific to your problem, keeping all IP yours). This allows the automation to improve over time, regardless of how the design evolves, escaping the parametric bottleneck.
If automation fails on a novel geometry, the engineer does what they would have done anyway: uploads the geometry, assigns boundary conditions and mesh configurations themselves, and continues. The setup cost of this approach converges toward zero. You start by exploring and simulating normally — every correction you make along the way becomes a test case. By the time you come back to the next round of designs, the AI has used those cases offline to improve the automation logic. You don’t need to predict the future, because the system learns in real-time as you work.
One expert-defined simulation setup supports an entire design team exploring freely across novel geometries. Analysts review exceptions, not every run.
We’re building for teams where speed to market matters more than optimisation performance. Startups and scale-ups iterating weekly on fundamentally different designs, not refining the same one for months, including robotics, bioreactors, micro-mobility, fusion energy, wind turbines, the next generation of energy technology, and an expanding set of industries.
If these bottlenecks feel familiar, or if setting up generative studies hasn’t been practical yet, we’d like to hear from you.
Sweet! Been looking forward to hearing more for a while...